How to choose the right Speech to Text & Text to Speech engine
The essential criteria for selecting the best voice engines for your AI agents.
STT Evaluation Criteria
Speed (Latency)
Latency should be < 1200ms. Streaming mode is preferred for a smooth user experience.
Accuracy (WER)
Word Error Rate should enable > 92% comprehension for natural interaction.
Geography & GDPR
Critical for compliance: French/EU vs. American engines. Data hosting location matters.
Pricing
Cost varies significantly between providers and usage modes: real-time (live) vs. batch transcription. Compare based on your call volume.
Key Technical Concepts
Speechtimeout
Silence management during dictation. Essential for capturing information like tracking numbers or zip codes.
Protocols
MRCP and WebSocket support for flexible integration with your existing telecom infrastructure.
Voice Biometrics
Integration with Whispeak for real-time user authentication and fraud detection.
Multilingual
Native support for multiple languages and dialects for international deployments.
Let's dive into the details of an STT engine
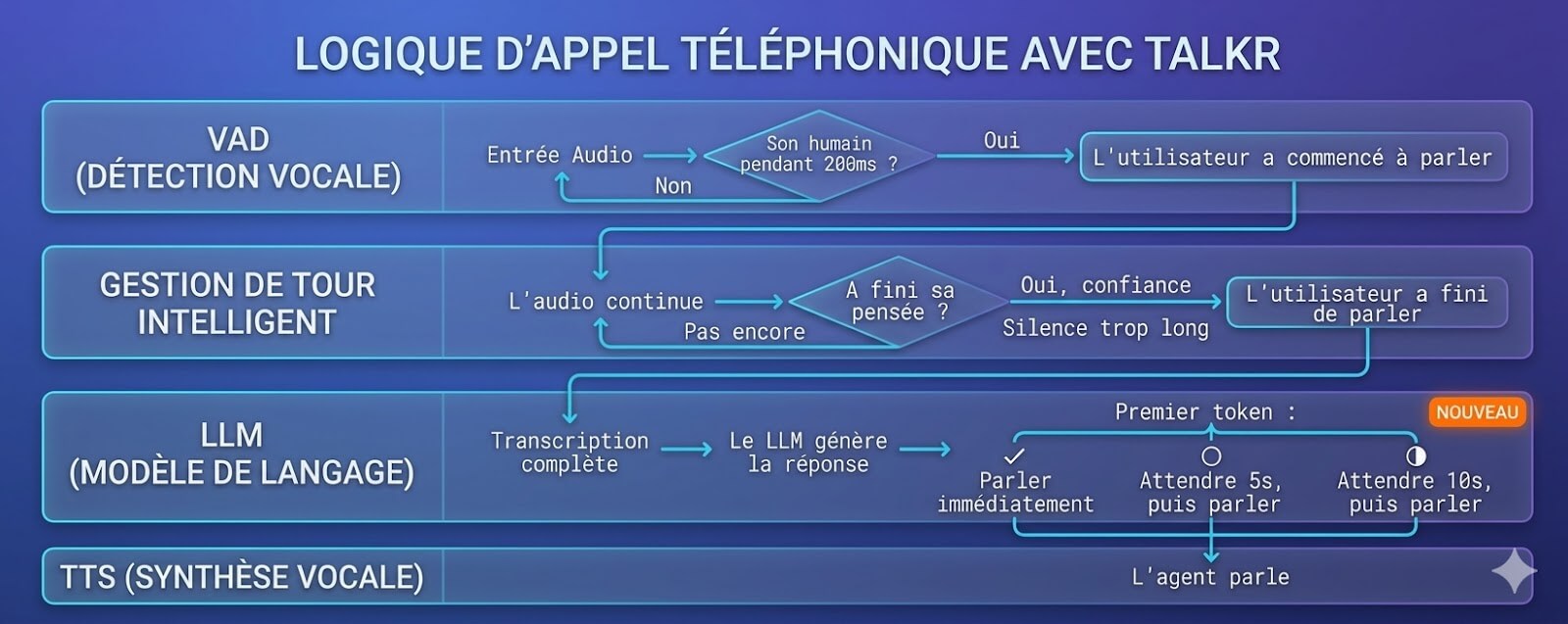
Have you heard of Speechtimeout?
Real-time streaming API for voicebots
Stream for voicebots, or Stream Human to Bots (Stream H2B), is a set of APIs that enable clients to create an interaction between an end user and a bot - for example, to build an interactive voice response (IVR) system on the phone, or a voicebot within an application.
Two available protocols
Two protocols provide access to this API's features:
Authentication and authorization via the MRCP protocol. The payload is encoded in XML. Ideal for traditional telecom infrastructure and voice standards.
Authentication and authorization via WebSocket. The payload is encoded in JSON. Ideal for modern web applications and cloud-native integrations.
These protocols differ primarily in their application layer and payload format. Beyond that, both offer the same feature set.
The famous SpeechTimeout
Certain functions allow listening for varying durations of the audio signal - for example, when someone is dictating a tracking number and pauses mid-sentence. Without a properly configured SpeechTimeout, the system cuts off the conversation prematurely.
SpeechTimeout is the parameter that defines the maximum wait time for a voice signal. It prevents conversation interruption during natural silences, thinking pauses, or slow dictation, ensuring a smooth, non-frustrating user experience.
The problem nobody solves... except TALKR
Most STT engines fail miserably on structured data dictated verbally: license plates ("Alpha Bravo 123 Charlie Delta"), tracking numbers, customer references, zip codes, IBANs... The engine hears words but doesn't understand it's a formatted identifier.
Result: massive transcription errors where accuracy is critical - impossible to find a package, vehicle, or customer file.
The TALKR solution: Real-time Multi-LLM
TALKR orchestrates multiple LLMs within a single conversation: while one model handles natural dialogue, a second specializes in extracting and validating structured data (plates, numbers, references). Both collaborate in real time to deliver comprehension that STT engines alone can't achieve.
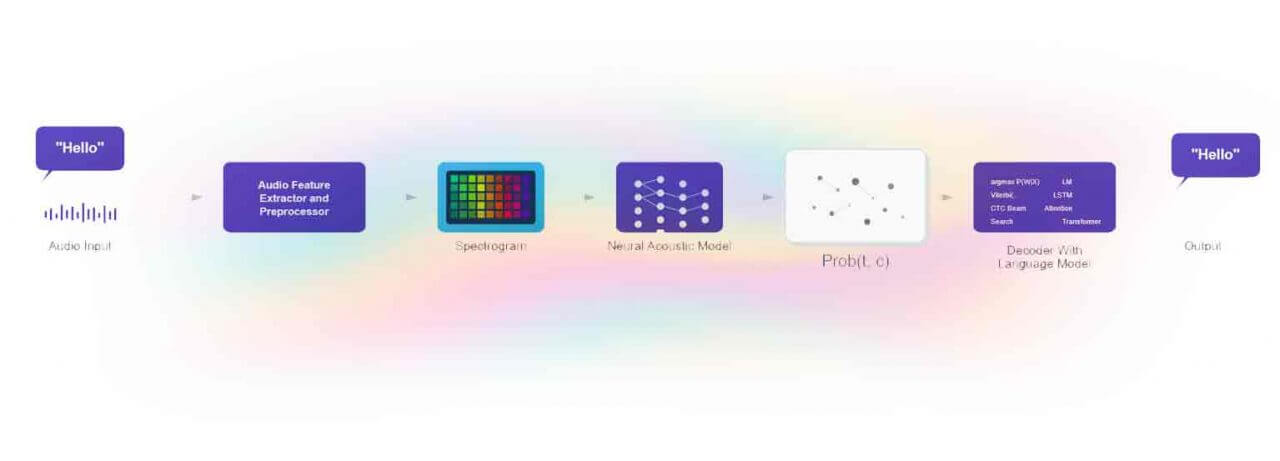
Internal architecture of an STT engine - from raw audio signal to text transcription. Parameters like SpeechTimeout act on the acoustic segmentation layer.
Speech to Text engines integrated with TALKR
TALKR is compatible with the best speech recognition engines on the market. Choose the one that matches your use case, latency constraints, and sovereignty requirements.

Google Cloud STT
Google's reference engine. Excellent multilingual coverage (125+ languages), telephony-optimized models, real-time streaming, and contextual adaptation.

Whisper (OpenAI)
OpenAI's open-source model known for robustness against ambient noise and exceptional multilingual accuracy. Ideal for high-fidelity transcription.
Deepgram
Ultra-fast engine based on an end-to-end model. Among the lowest latency on the market - perfect for real-time callbots requiring instant responses.

Gladia
French startup specializing in STT. Unified multi-engine API, EU hosting, native GDPR compliance. Ideal for sovereign projects.

Allomedia
French voice analytics solution. Specializing in phone conversation understanding and business insight extraction.

Voxist
French speech transcription technology optimized for voicemail and smart answering. Specialist in telephone voice recognition for French.
Kaldi
Historic open-source ASR framework. Reference for fine-tuning acoustic models - reminiscent of the Nuance era. Ideal for on-premise deployments and advanced speech recognition model customization.
Gradium
Paris-based startup founded by the Kyutai team (ex-Meta, Google DeepMind). Precise transcription and real-time voice synthesis with ultra-low latency. Raised €60M seed in December 2025.
 Low latency
Multilingual
Real-time
Low latency
Multilingual
Real-time
The invisible challenge of voice AI: detecting real interruptions
One of the hardest problems in voice AI isn't understanding speech - it's precisely detecting interruptions. Most systems rely on simple Voice Activity Detection (VAD). The problem: a cough, an "mm-hmm", an "I see", or background noise can trigger VAD - making the agent jittery and robotic.
Cuts off speech at the slightest sound. Interprets acknowledgments as interruptions. Choppy, frustrating conversations.
Some engines (Deepgram, Neuphonic) include contextual detection that distinguishes a real "stop" from simple vocal feedback. Natural, fluid conversations.
TALKR lets you configure VAD sensitivity per agent and choose an STT engine suited to your use case - so your AI agents talk like humans, not robots.
TALKR lets you combine and switch between these STT engines based on your needs: latency, accuracy, sovereignty, or cost.
Choose my STT engine → See all voice integrations →TALKR is a member of Le Voice Lab
Le Voice Lab is the leading French association that brings together voice and conversational AI players. It unites startups, large corporations, and researchers to promote voice innovation in France and Europe.
Katya Laine, founder of TALKR.ai, has been co-founder and Vice President since 2019 - a strong commitment to structuring and championing the French voice ecosystem.

Natural voice, the ultimate differentiator
Did you know voice is essential for improving user experience? Respond to your users with a neural voice that radically transforms perceived quality.

Deliver a memorable experience
with custom voices
ElevenLabs' mission is to make multilingual audio on demand a reality in real-time conversation streaming for callbots.
ElevenLabs uses a deep learning model to generate voices with unprecedented human-like tone and intonation accuracy. Thanks to near-real-time voice cloning, it's possible to synthesize an almost natural-sounding voice over the phone.
Its research lab continuously feeds platform features: SSML, emotion, paralinguistics - and contributes to the ultimate goal of instantly converting spoken audio between languages.
I want an ElevenLabs voice →
"Keep phone sentences short - it impacts reading speed. You need to send text and receive MP3 on the fly very quickly."
- TALKR Tip
"Find the voice that will represent your brand. Clean up background noise that can hurt the quality of the voice generated on the fly."
- TALKR Tip

"For your users, the best experience comes when there's a match between voice quality, intonation, and comprehension."
- TALKR Tip

"Real-time API integration: TALKR and Genesys, the winning duo to give voice to your conversations."
- TALKR Tip
Voice cloning & emotional personalization
In just a few months, ElevenLabs has become the go-to TTS tool. After finer tuning, it's possible to adjust the tone and variability of the voice to make it less robotic. Adding this emotional dimension strengthens quality.
The AI dubbing tool lets users automatically use their voice on the phone in a different language, while preserving the original speaker's voice.
Being able to offer voices with slight regional accents also enhances voice quality for a fully immersive voice experience. The key is finding a voice perfectly suited to the use case: from deep voices to crystal-clear ones - we help you find the best solution.
Performance & watch points
Models keep evolving to add emotion and paralinguistics. If the expected MP3 takes a bit long, some voice distortion can occur - voice stability directly impacts comprehension.
We also noticed some numbers were read in English rather than the target language, but the fix came quickly. It's essential to have a perfect-quality audio sample for cloning.
The arrival of paralinguistics will propel ElevenLabs as the #1 voice cloning player. Its pricing can still hold back some deployments: the average cost of three interactions exceeds 4 cents using the ElevenLabs API.
TALKR & Genesys - The winning duo
Combine the power of Genesys CCaaS with ElevenLabs neural voices powered by TALKR for a next-generation callbot experience. A real-time API integration designed for enterprise.

ElevenLabs voice cloning lets you create a unique brand voice or faithfully reproduce an existing voice for your telephone AI agents.
An integration built for callbots
Creating any voice is child's play with ElevenLabs. The TALKR platform natively integrates it via API so every response from your agent is rendered in real time with your brand voice.
Voices are increasingly realistic. The latest models now handle emotion, paralinguistics, and regional nuances - for total conversational immersion on the user side.
Test an ElevenLabs voice →
Text to Speech engines integrated with TALKR
TALKR is compatible with the best speech synthesis engines on the market. Choose the one that matches your use case, quality constraints, and sovereignty requirements.
ElevenLabs
World leader in neural speech synthesis. Voice cloning, emotion, paralinguistics, regional accents. Exceptional quality for real-time callbots.

Voxygen
French speech synthesis technology. Expressive, natural voices with sovereign hosting in France. Custom voice specialist for enterprises.
Acapela
Advanced TTS engine with natural, expressive voices. Multilingual support and fast API integration for conversational agents.
Whisper (OpenAI)
OpenAI's model also available as TTS. Natural, multilingual, fluid voices. Simple API integration with remarkable quality.
PlayHT
AI speech synthesis platform with instant voice cloning. Large voice library, ultra-fast streaming, and real-time API.

Soniox
Next-generation voice AI engine. Low-latency speech synthesis, ideal for real-time conversational interactions.

DeepHub
High-performance TTS solution with multilingual support and high-quality neural voices. Optimized for large-scale deployments.

Speechmatics
Cutting-edge British technology. Excellent accuracy on accents and dialects, high compliance, and enterprise support.

Deepgram
Ultra-fast engine with among the lowest latency on the market. Aura model for real-time speech synthesis and streaming.
Rime
Speech synthesis optimized for conversational agents. Natural voices with fine control over prosody and intonation.

WellSaid
Studio-quality AI voices. Ideal for professional use cases requiring flawless audio quality and brand voices.
 Studio qualityBrand voicePro
Studio qualityBrand voicePro
AssemblyAI
Complete voice AI platform with advanced TTS capabilities. Developer-friendly API and comprehensive documentation.

Verbio
Spanish solution specializing in voice for contact centers. Multilingual TTS with focus on Latin and European languages.

Kokoro
Lightweight, performant open-source TTS model. Expressive voices with excellent quality-to-cost ratio - ideal for on-premise deployments.
TALKR lets you combine and switch between these TTS engines based on your needs: voice quality, latency, cost, or sovereignty.
Choose my TTS engine →