Comment choisir un bon moteur Speech to Text & Text to Speech ?
Les critères essentiels pour sélectionner les meilleurs moteurs vocaux pour vos agents IA.
STT (Speech-to-Text) et TTS (Text-to-Speech) sont les deux couches vocales d'un agent IA conversationnel : le STT transcrit la parole de l'utilisateur en texte (latence cible < 700ms, WER < 8% pour le français), le TTS restitue la réponse du LLM en voix synthétique (latence cible < 300ms). Le choix de ces moteurs détermine directement la naturalité et la fluidité perçue de l'agent.
🎯 Le bon compromis : 5 critères à équilibrer
Chaque moteur vocal a ses forces. Le choix idéal dépend de votre cas d'usage - survolez chaque critère pour comprendre les enjeux.
👆 Survolez un critère pour découvrir les enjeux
Critères d'évaluation des STT
Vitesse (Latence)
La latence doit être < 700ms. Le mode streaming est préférable pour une expérience utilisateur fluide.
Précision (WER)
Le Word Error Rate doit permettre > 92% de compréhension pour une interaction naturelle.
Géographie & RGPD
Crucial pour la conformité : moteurs français/EU vs. américains. Hébergement des données en France.
Tarif
Le coût varie fortement selon les fournisseurs et le mode d'utilisation : transcription en temps réel (live) ou en différé (batch). À comparer selon votre volume d'appels.
Concepts techniques clés
Speechtimeout
Gestion du silence pendant la dictée. Essentiel pour la saisie d'informations comme les numéros de suivi ou codes postaux.
Protocoles
Support MRCP et WebSocket pour une intégration flexible avec vos infrastructures télécom existantes.
Biométrie vocale
Intégration avec Whispeak pour l'authentification utilisateur en temps réel et la détection de fraude.
Multilingue
Support natif de multiples langues et dialectes pour les déploiements internationaux.
Rentrons dans le détail d'un moteur STT
Avez-vous entendu parler du Speechtimeout ?
API de flux en temps réel pour les voicebots
Stream pour les voicebots, ou Stream Human to Bots (Stream H2B), est un ensemble d'API permettant aux clients de créer une interaction entre un utilisateur final humain et un bot - par exemple pour créer une réponse vocale interactive (IVR) sur le téléphone, ou un voicebot au sein d'une application.
Deux protocoles disponibles
Deux protocoles permettent d'accéder aux fonctionnalités de cette API :
Authentification et autorisation via le protocole MRCP. La charge utile est encodée en XML. Idéal pour les infrastructures télécom traditionnelles et les standards voix.
Authentification et autorisation via WebSocket. La charge utile est encodée en JSON. Idéal pour les applications web modernes et les intégrations cloud-native.
Ces protocoles diffèrent principalement par leur couche d'application et la nature de leur charge utile. Au-delà de cela, les deux offrent le même ensemble de fonctionnalités.
Le fameux SpeechTimeout
Certaines fonctions permettent d'écouter plus ou moins longtemps le signal sonore - par exemple quand une personne dicte un numéro de colis et s'arrête au milieu de la phrase. Sans SpeechTimeout correctement configuré, le système coupe la conversation prématurément.
Le SpeechTimeout est le paramètre qui définit la durée maximale d'attente d'un signal vocal. Il évite la rupture de la conversation lors des silences naturels, pauses de réflexion ou dictées lentes, garantissant une expérience utilisateur fluide et non frustrante.
Le problème que personne ne résout… sauf TALKR
La plupart des moteurs STT échouent lamentablement sur les données structurées dictées à l'oral : plaques d'immatriculation ("Alpha Bravo 123 Charlie Delta"), numéros de colis, références client, codes postaux, IBAN… Le moteur entend des mots, mais ne comprend pas qu'il s'agit d'un identifiant formaté.
Résultat : des erreurs de transcription massives là où la précision est critique - impossible de retrouver un colis, un véhicule ou un dossier client.
La solution TALKR : le Multi-LLM en temps réel
TALKR orchestre plusieurs LLM au sein d'une même conversation : pendant qu'un modèle gère le dialogue naturel, un second est spécialisé dans l'extraction et la validation des données structurées (plaques, numéros, références). Les deux collaborent en temps réel pour offrir une compréhension que les moteurs STT seuls ne peuvent atteindre.
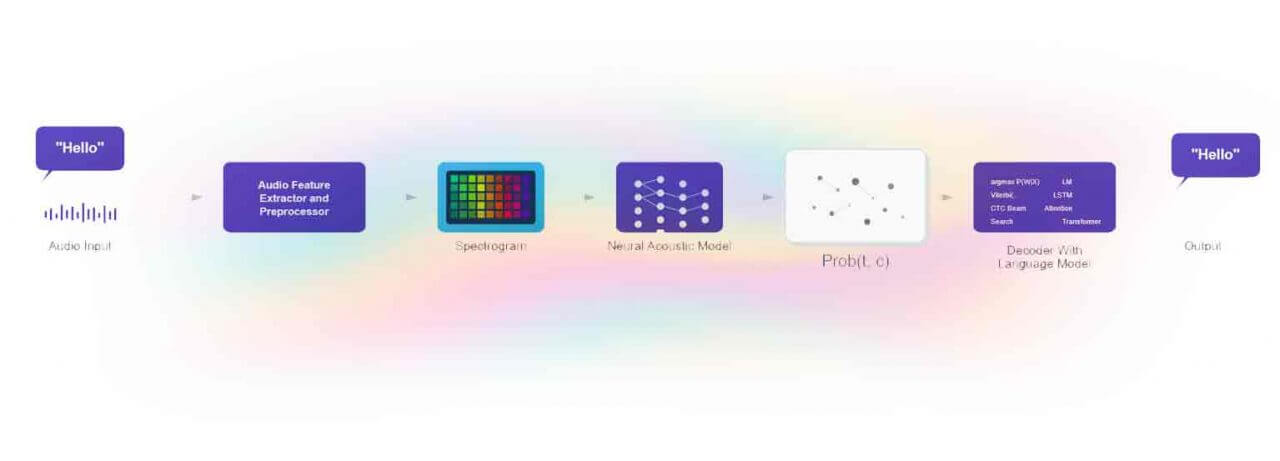
Architecture interne d'un moteur STT - du signal audio brut à la transcription texte. Les paramètres comme le SpeechTimeout agissent sur la couche de segmentation acoustique.
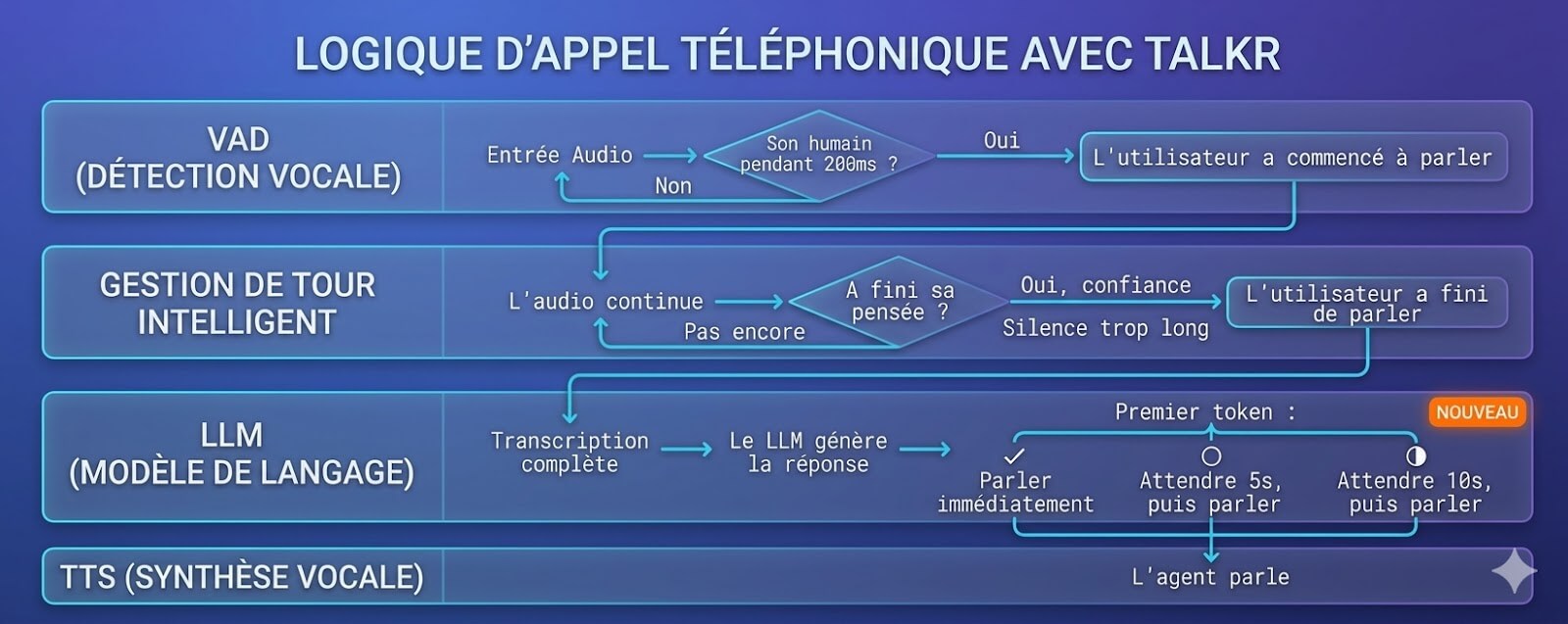
Les moteurs Speech to Text intégrés à TALKR
TALKR est compatible avec les meilleurs moteurs de reconnaissance vocale du marché. Choisissez celui qui correspond à votre cas d'usage, vos contraintes de latence et de souveraineté.
Noms complexes, plaques d'immatriculation, codes longs... en environnement bruyant ?
Si vous avez besoin d'un agent capable de comprendre parfaitement des noms de famille difficiles, des adresses, des plaques d'immatriculation ou des codes longs dans un environnement bruyant, TALKR est la solution grâce à ses différents moteurs STT. Chaque moteur est évalué sur sa robustesse au bruit, sa précision sur les entités nommées et sa capacité à gérer des vocabulaires métier spécifiques.

Google Cloud STT
Le moteur de référence de Google. Excellente couverture multilingue (125+ langues), modèles optimisés pour la téléphonie, streaming temps réel et adaptation contextuelle.
 Multilingue
Streaming
Téléphonie
Multilingue
Streaming
Téléphonie

Whisper (OpenAI)
Modèle open-source d'OpenAI reconnu pour sa robustesse face au bruit ambiant et sa précision multilingue exceptionnelle. Idéal pour la transcription haute fidélité.
Open Source
Anti-bruit
99 langues
Deepgram
Moteur ultra-rapide basé sur un modèle end-to-end. Latence parmi les plus basses du marché, parfait pour les callbots temps réel nécessitant des réponses instantanées.
Ultra-rapide
End-to-end
Temps réel

Gladia
Startup française spécialisée dans le STT. API unifiée multi-moteurs, hébergement EU, conformité RGPD native. Idéal pour les projets souverains.
 RGPD
Multi-moteurs
RGPD
Multi-moteurs

Allomedia
Solution française d'analyse vocale et speech analytics. Spécialisée dans la compréhension des conversations téléphoniques et l'extraction d'insights business.
Speech Analytics
Téléphonie

Voxist
Technologie française de transcription vocale optimisée pour la messagerie et le répondeur intelligent. Spécialiste de la voix téléphonique en français.
Messagerie
Voix télécom
Kaldi
Framework open-source historique pour l'ASR. Référence en fine-tuning de modèles acoustiques - rappelant l'époque Nuance. Idéal pour les déploiements on-premise et la personnalisation avancée des modèles de reconnaissance vocale.
Open Source
Fine-tuning ASR
On-premise

Pyannote.ai
Spécialiste de la diarisation et de la segmentation du locuteur. Pyannote.ai identifie qui parle et quand dans un flux audio multi-intervenants - idéal pour les centres de contact et la transcription de réunions.
Diarisation
Multi-locuteurs
API
Gradium
Startup parisienne fondée par l'équipe Kyutai (ex-Meta, Google DeepMind). Transcription précise et synthèse vocale temps réel avec une latence ultra-faible. 60M€ levés en seed dès décembre 2025.
Faible latence
Multilingue
Temps réel
Le défi invisible de l'IA vocale : détecter les vraies interruptions
L'un des problèmes les plus difficiles de l'IA vocale n'est pas de comprendre la parole - c'est de détecter précisément les interruptions. La plupart des systèmes reposent sur une simple détection d'activité vocale (VAD). Le problème : une toux, un « mm-hmm », un « je vois » ou un bruit de fond suffisent à déclencher la VAD - rendant l'agent nerveux et robotisé.
Coupe la parole au moindre son. Interprète les acquiescements comme des interruptions. Conversations saccadées et frustrantes.
Certains moteurs (Deepgram, Neuphonic) intègrent une détection contextuelle qui distingue un vrai « stop » d'un simple feedback vocal. Conversations naturelles et fluides.
TALKR permet de configurer le seuil de sensibilité VAD par agent et de choisir un moteur STT adapté à votre cas d'usage - pour que vos agents IA parlent comme des humains, pas comme des robots.
Votre solution STT
Vous utilisez un moteur STT qui n'est pas dans cette liste ? TALKR intègre des solutions de reconnaissance vocale à la demande. Envoyez-nous la documentation de votre API.
Demander une intégration →TALKR vous permet de combiner et switcher entre ces moteurs STT selon vos besoins : latence, précision, souveraineté ou coût.
Choisir mon moteur STT → Voir les moteurs TTS →TALKR est membre du Voice Lab
Le Voice Lab est l'association française de référence qui fédère les acteurs de la voix et de l'IA conversationnelle. Elle rassemble startups, grands groupes et chercheurs pour promouvoir l'innovation vocale en France et en Europe.
Katya Lainé, fondatrice de TALKR.ai, en est co-fondatrice et Vice-Présidente depuis 2019 - un engagement fort pour structurer et faire rayonner l'écosystème vocal français.

La voix naturelle, l'enjeu absolu
Saviez-vous que la voix est essentielle pour améliorer l'expérience utilisateur ? Répondez à vos utilisateurs avec une voix neurale qui transforme radicalement la qualité perçue.

Faites vivre une expérience
mémorable avec des voix sur mesure
La mission d'ElevenLabs est de rendre les audios multilingues à la demande une réalité dans le streaming des conversations en temps réel pour les callbots.
Eleven Labs utilise un modèle d'apprentissage profond pour générer les voix avec un ton et une intonation humains d'une précision sans précédent. Grâce au clonage de voix en temps quasi réel, il est possible de synthétiser au téléphone une voix presque naturelle.
Son studio de recherche alimente les fonctionnalités de la plateforme en permanence : SSML, émotion, paralinguistique - et contribue à réaliser l'objectif ultime de convertir instantanément l'audio parlé entre les langues.
Je souhaite une voix ElevenLabs →
« Préparez des phrases pas trop longues au téléphone car cela impacte la vitesse de lecture - il faut envoyer le texte et récupérer un MP3 à la volée de manière très rapide. »
- Conseil TALKR
« Trouvez la voix qui va représenter votre marque. Nettoyez le fond et le bruit qui peut nuire à la qualité de la voix générée à la volée. »
- Conseil TALKR

« Pour vos utilisateurs, la meilleure expérience se fait lorsqu'il y a une adéquation entre la qualité de la voix et son intonation en fonction de la compréhension. »
- Conseil TALKR

« Intégration temps réel par API : TALKR et Genesys, le duo gagnant pour donner de la voix à vos conversations. »
- Conseil TALKR
Clonage vocal & personnalisation émotionnelle
En quelques mois, ElevenLabs est devenu l'outil incontournable du TTS. Après des réglages plus précis, il est possible de paramétrer la tonalité et la variabilité de la voix pour lui donner un côté moins robotique. En ajoutant ce côté émotionnel, cela renforce la qualité.
L'outil de doublage IA permet aux utilisateurs d'utiliser automatiquement leur voix au téléphone dans une langue différente, tout en préservant la voix de l'orateur original.
Pouvoir proposer des voix avec de légers accents marseillais ou toulousain renforce aussi la qualité du timbre pour une expérience vocale en immersion totale. L'important est de trouver une voix totalement adaptée au use case : entre voix grave ou voix cristalline - nous vous aidons à dénicher la meilleure solution.
Performances & points de vigilance
Les modèles ne cessent d'évoluer pour ajouter de l'émotion et du paralinguistique. Si le MP3 attendu est un peu long, on peut rencontrer une certaine déformation de la voix - la stabilité de la voix influe directement sur la compréhension.
On a également constaté que certains nombres étaient lus en anglais plutôt qu'en français, mais la correction s'est vite réalisée. Il est essentiel d'avoir un échantillon sonore de parfaite qualité pour le clonage.
L'arrivée du paralinguistique va propulser ElevenLabs qui devient l'acteur n°1 du clonage vocal. C'est son tarif qui peut encore freiner certains déploiements : le coût moyen de trois interactions dépasse les 4 centimes en utilisant l'API ElevenLabs.
TALKR & Genesys - Le duo gagnant
Combinez la puissance du CCaaS de Genesys avec les voix neurales ElevenLabs pilotées par TALKR pour une expérience callbot de nouvelle génération. Une intégration API temps réel pensée pour les grands comptes.

Le clonage vocal ElevenLabs permet de créer une voix de marque unique ou de reproduire fidèlement une voix existante pour vos agents IA téléphoniques.
Une intégration pensée pour les callbots
Créer n'importe quelle voix est un jeu d'enfant avec ElevenLabs. La plateforme TALKR l'intègre nativement via API pour que chaque réponse de votre agent soit rendue en temps réel avec la voix de votre marque.
Les voix sont toujours plus réalistes. Les modèles les plus récents gèrent désormais l'émotion, le paralinguistique et les nuances régionales - pour une immersion conversationnelle totale côté utilisateur.
Tester une voix ElevenLabs →
Les moteurs Text to Speech intégrés à TALKR
TALKR est compatible avec les meilleurs moteurs de synthèse vocale du marché. Choisissez celui qui correspond à votre cas d'usage, vos contraintes de qualité et de souveraineté.
ElevenLabs
Leader mondial de la synthèse vocale neurale. Clonage vocal, émotion, paralinguistique, accents régionaux. Qualité exceptionnelle pour les callbots temps réel.
Clonage vocal
Émotion
Temps réel

Voxygen
Technologie française de synthèse vocale. Voix expressives et naturelles, hébergement souverain en France. Spécialiste des voix sur mesure pour les entreprises.
Voix sur mesure
Souverain
Acapela
Moteur TTS avancé avec des voix naturelles et expressives. Support multilingue et intégration API rapide pour les agents conversationnels.
 Multilingue
API rapide
Expressif
Multilingue
API rapide
Expressif
Whisper (OpenAI)
Le modèle d'OpenAI également disponible en TTS. Voix naturelles, multilingues et fluides. Intégration simple via API avec une qualité remarquable.
Multilingue
API simple
Naturel
PlayHT
Plateforme de synthèse vocale IA avec clonage vocal instantané. Large bibliothèque de voix, streaming ultra-rapide et API temps réel.
Clonage vocal
Streaming
Ultra-rapide

Soniox
Moteur IA vocal de nouvelle génération. Synthèse vocale basse latence, idéal pour les interactions conversationnelles en temps réel.
Basse latence
Temps réel
IA avancée

DeepHub
Solution TTS performante avec support multilingue et voix neurales de haute qualité. Optimisé pour les déploiements à grande échelle.

Speechmatics
Technologie britannique de pointe. Excellente précision sur les accents et dialectes, conformité élevée et support entreprise.
 UK
Accents
Entreprise
Conformité
UK
Accents
Entreprise
Conformité

Deepgram
Moteur ultra-rapide avec une latence parmi les plus basses du marché. Modèle Aura pour la synthèse vocale temps réel et streaming.
Ultra-rapide
Aura TTS
Streaming
Rime
Synthèse vocale optimisée pour les agents conversationnels. Voix naturelles avec contrôle fin de la prosodie et de l'intonation.
Prosodie
Conversationnel
Contrôle fin

WellSaid
Voix IA de qualité studio. Idéal pour les cas d'usage professionnels nécessitant une qualité audio irréprochable et des voix de marque.
 Qualité studio
Voix de marque
Pro
Qualité studio
Voix de marque
Pro

AssemblyAI
Plateforme IA vocale complète avec des capacités TTS avancées. API développeur-friendly et documentation exhaustive.
API complète
Dev-friendly
Avancé

Verbio
Solution espagnole spécialisée dans la voix pour les centres de contact. TTS multilingue avec focus sur les langues latines et européennes.
 Contact center
Langues latines
Contact center
Langues latines
Google Cloud TTS
Synthèse vocale WaveNet et Neural2 de Google. Plus de 380 voix dans 50+ langues, SSML avancé avec réglage fin du débit, de la hauteur et des pauses - rendu très naturel et coût faible.
WaveNet / Neural2
380+ voix
SSML
Telnyx
Opérateur télécom cloud avec STT et TTS intégrés dans la même infrastructure. Latence réduite pour les agents vocaux hébergés sur leur réseau, facturation unifiée téléphonie + voix.
STT + TTS
Téléphonie cloud
Neuphonic
Moteur TTS ultra-basse latence concu pour les agents IA conversationnels en temps réel. Voix expressives avec une latence inférieure à 100 ms - parfait pour les callbots exigeant une fluidité maximale.
TTS <100ms
Temps réel

Kokoro
Modèle TTS open-source léger et performant. Voix expressives avec un excellent rapport qualité/coût, idéal pour les déploiements on-premise.
Gradium
Moteur TTS développé par Gradium, spin-off de Kutai. Voix naturelles et souveraines, conçu pour les entreprises exigeant confidentialité et performance.
Souverain
Entreprise
On-premise
TALKR vous permet de combiner et switcher entre ces moteurs TTS selon vos besoins : qualité vocale, latence, coût ou souveraineté.
Choisir mon moteur TTS →Questions fréquentes — STT & TTS
Les réponses aux questions les plus courantes sur les moteurs Speech-to-Text et Text-to-Speech pour les agents IA.
Un moteur STT convertit la parole audio en texte en temps réel. Dans un callbot, c'est la première brique : il transcrit ce que dit l'utilisateur pour que le LLM puisse le comprendre. Les critères clés sont la latence (cible < 700ms) et le WER (Word Error Rate < 8% pour le français) en mode streaming.
Un moteur TTS convertit le texte généré par le LLM en parole synthétique restituée à l'utilisateur. Les meilleurs moteurs (ElevenLabs, Google WaveNet, Azure Neural TTS) produisent une voix quasi-humaine avec une latence inférieure à 300ms. Le choix de la voix et la prosodie impactent directement la satisfaction des utilisateurs.
Le STT streaming transcrit la parole mot par mot pendant que l'utilisateur parle (latence < 500ms). Le STT batch traite un fichier audio complet après enregistrement. Pour un agent vocal conversationnel, le streaming est indispensable. Le batch est réservé à l'analyse différée et à la retranscription d'appels.
Le WER (Word Error Rate) mesure le pourcentage de mots mal transcrits. Un WER de 8% signifie 8 mots incorrects sur 100. Au-delà de 10%, la compréhension du LLM se dégrade et l'agent génère des réponses hors-sujet. TALKR exige un WER < 8% pour valider un moteur STT en production.
Pour le français en contexte callbot, Deepgram Nova-2 (latence < 300ms, WER ~6%), Google Speech-to-Text v2 (WER ~5%, excellent sur les accents régionaux) et Whisper large-v3 (WER ~4%, idéal pour les vocabulaires métier) sont les références. TALKR permet de configurer le moteur optimal selon votre secteur et votre volume d'appels.