à quoi sert la tokenisation des mots dans le domaine du language ?
📅 24 mai 2023⏱️ 3 min de lecture📝 581 mots
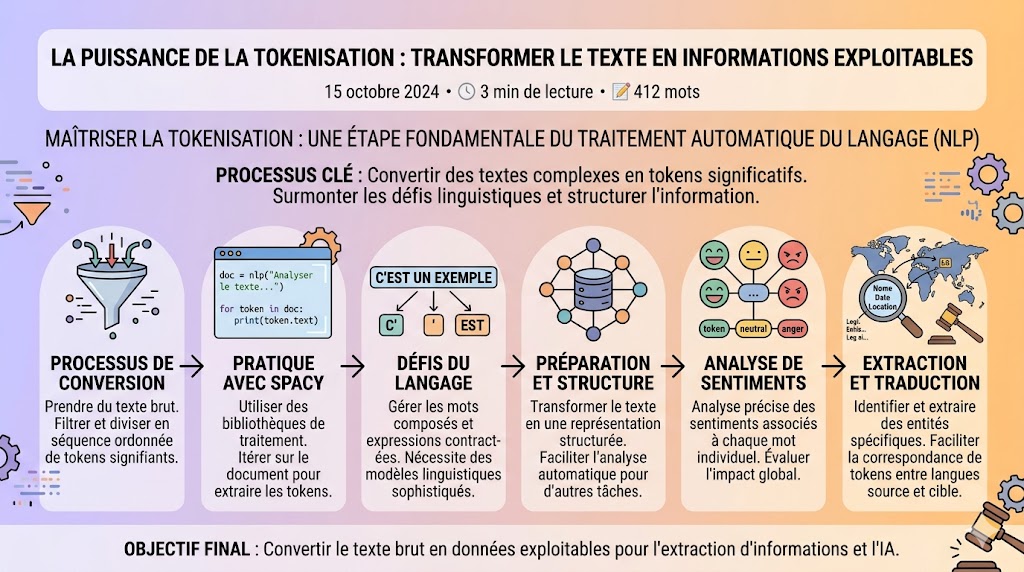
La puissance de la tokenisation : transformer le texte en informations exploitables
Introduction: La tokenisation est une méthode fondamentale en traitement automatique du langage naturel (NLP) qui permet de convertir un texte en une séquence de tokens significatifs. Bien qu'apparente à une tâche simple, elle présente des défis spécifiques, notamment lorsqu'il s'agit de gérer des cas particuliers tels que les mots composés ou les expressions contractées. Dans cet article, nous explorerons en détail la tokenisation et son utilisation dans le domaine du NLP, mettant en évidence son rôle essentiel dans la compréhension automatique du langage.
La tokenisation en pratique : Lorsque nous travaillons avec des bibliothèques de NLP telles que spaCy, la tokenisation est souvent la première étape du pipeline de traitement du texte. En utilisant spaCy, nous pouvons facilement itérer sur un document pour obtenir une séquence ordonnée de tokens. Par exemple, en utilisant la variable "nlp", qui représente le texte de manière interprétable par la bibliothèque, nous pouvons accéder aux tokens de la manière suivante :
import spacy
nlp = spacy.load("fr_core_news_sm") doc = nlp("Analyser le texte avec spaCy est un jeu d'enfant.")
for token in doc: print(token.text)
Dans cet exemple, nous utilisons la bibliothèque spaCy chargée avec un modèle spécifique à la langue française ("fr_core_news_sm"). Nous créons ensuite un objet "doc" en appliquant le modèle à notre texte. En itérant sur ce document, nous pouvons accéder à chaque token individuel et le traiter selon nos besoins.
Les défis de la tokenisation : La tokenisation peut sembler une tâche simple, mais elle nécessite une attention particulière pour gérer les subtilités du langage. Par exemple, en français, les mots composés et les expressions contractées posent souvent problème. Considérons l'exemple de la phrase "C'est un exemple". Ici, la tokenisation doit séparer le "C'" comme premier mot et considérer "est" comme un deuxième mot, tout en maintenant l'association avec "C'". Ces défis linguistiques nécessitent des modèles sophistiqués et des approches spécifiques pour obtenir une tokenisation précise et cohérente.
L'utilité de la tokenisation : La tokenisation joue un rôle essentiel dans de nombreuses tâches de NLP. Elle permet de préparer le texte pour des tâches telles que la classification de texte, l'analyse des sentiments, l'extraction d'informations et bien d'autres encore. En convertissant le texte en tokens, nous obtenons une représentation structurée qui facilite l'analyse automatique.
Exemples d'utilisation de la tokenisation :
Analyse de sentiment : La tokenisation est utilisée pour diviser les phrases en mots individuels, permettant ainsi une analyse précise des sentiments associés à chaque mot et leur impact global sur le texte.
Extraction d'informations : En tokenisant le texte, nous pouvons identifier et extraire des entités spécifiques, telles que des noms de personnes, des lieux ou des dates, qui sont essentiels dans des domaines tels que le traitement des documents juridiques ou le suivi des médias sociaux.
Traduction automatique : La tokenisation est cruciale dans les systèmes de traduction automatique, où elle permet de diviser le texte source et le texte cible en tokens correspondants, facilitant ainsi la correspondance et la transformation d'une langue à une autre.
La tokenisation est une étape fondamentale en NLP qui transforme le texte brut en une séquence de tokens significatifs. En utilisant des bibliothèques de NLP telles que spaCy, nous pouvons facilement appliquer cette méthode et itérer sur les tokens obtenus pour des analyses plus poussées. La tokenisation est essentielle dans de nombreuses tâches de NLP, offrant une base solide pour l'analyse de texte, l'extraction d'informations et bien d'autres applications passionnantes dans le domaine de l'IA.
FAQ - Tokenisation dans le traitement du langage naturel
Quelle est la difference entre la tokenisation par mot, par caractere et par sous-mot (BPE) ?
La tokenisation par mot decoupe le texte aux espaces et ponctuations : chaque mot devient un token. Elle est simple mais produit un vocabulaire tres large (plusieurs centaines de milliers de tokens pour une langue europeenne) et ne gere pas les mots inconnus. La tokenisation par caractere reduit le vocabulaire a 100-200 symboles mais produit des sequences tres longues, ce qui alourdit les calculs. La tokenisation par sous-mot, utilisee par la quasi-totalite des LLMs modernes (BPE, SentencePiece, WordPiece), offre un compromis : les mots frequents restent entiers, les mots rares sont decoupes en sous-unites connues. "Tokenisation" devient par exemple ["Token", "isation"] dans le vocabulaire BPE, ce qui permet au modele de gerer des mots qu'il n'a jamais vus pendant l'entrainement.
Pourquoi le nombre de tokens est-il important pour les LLMs et comment l'optimiser ?
Les LLMs ont une fenetre de contexte limitee (128K a 1M tokens selon les modeles en 2026) et sont factures au nombre de tokens traites. Un token correspond en moyenne a 3/4 d'un mot en anglais et un peu moins en francais, car le francais utilise plus de caracteres par concept. Pour optimiser le nombre de tokens : supprimer les espaces et sauts de ligne superflus, eviter de repeter des instructions identiques dans le prompt systeme et le prompt utilisateur, utiliser des abreviations dans les messages intermediaires (pas dans les reponses visibles par l'utilisateur), et pour les bases documentaires RAG, pre-filtrer les passages pertinents plutot que d'envoyer des documents entiers. Un audit de la consommation de tokens sur un echantillon de conversations permet d'identifier les 20% de cas qui consomment 80% du budget.
Comment la tokenisation gere-t-elle les langues avec une morphologie complexe comme le finnois ou l'arabe ?
Les langues agglutinantes (finnois, turc, hongrois) et les langues semitiques (arabe, hebreu) posent des defis specifiques car un seul mot peut encoder plusieurs informations grammaticales. En finnois, "taloissanikin" signifie "aussi dans mes maisons" en un seul mot. Les tokeniseurs BPE entrainees sur ces langues decoupent ce mot en sous-unites pertinentes, mais la performance reste inferieure aux langues indoeuropeennes plus regulieres. Pour les applications multilingues, les modeles XLM-RoBERTa, mBERT ou les LLMs multilingues comme mT5 et Gemini sont entraines sur des corpus balances qui incluent ces langues difficiles. Pour les chatbots deployes dans plusieurs pays, il est recommande de tester specifiquement la precision sur les langues cibles plutot que d'extrapoler depuis les benchmarks en anglais.
Qu'est-ce qu'un token dans le contexte des LLMs et pourquoi ce n'est pas toujours un mot complet ?
Dans les LLMs modernes, un token est une unite de texte apprise statistiquement par le tokeniseur. Le vocabulaire est construit en observant les sequences de caracteres les plus frequentes dans le corpus d'entrainement : les sequences tres courantes (mots frequents, prepositions, articles) deviennent des tokens entiers, tandis que les sequences rares sont decoupees en plusieurs tokens. "Chat" sera un token unique, mais "chatbot" peut devenir ["chat", "bot"] ou ["chatb", "ot"] selon le tokeniseur. Cette fragmentation explique pourquoi les LLMs peuvent parfois faire des erreurs sur des operations qui semblent triviales (compter les lettres d'un mot, inverser l'orthographe) : ils manipulent des tokens, pas des caracteres, et certaines informations sont perdues lors du decoupage.
Comment la tokenisation affecte-t-elle la qualite des reponses d'un chatbot en francais ?
Le francais est legerement desavantage par rapport a l'anglais dans la plupart des tokeniseurs : les mots francais sont en moyenne plus longs (accents, terminaisons grammaticales complexes) et certains tokeniseurs ont ete entraines majoritairement sur du texte anglais. Concretement, une phrase en francais consomme 10 a 20% plus de tokens que son equivalent anglais, ce qui reduit legerement la fenetre de contexte effective. Plus important : les erreurs de tokenisation sur des mots specifiques peuvent degrader la qualite des reponses. Par exemple, des termes techniques metier tres specifiques peuvent etre decoupes de maniere non-intuitive, ce qui peut perturber la comprehension du modele. Pour un chatbot metier en francais, il est conseille de tester les termes cles du domaine dans le tokeniseur utilise et de les inclure explicitement dans les exemples du prompt systeme si necessaire.
Envie de tester un agent IA TALKR ?
Déployez votre premier agent en moins de 48h — sans engagement.